
Arnoud Engelfriet
Wetten die door computers kunnen worden gelezen. Dat is een van de nieuwste technologische trends die onderzoeksbureau Gartner recent selecteerde voor haar jaarlijkse “Hype Cycle”, die onlangs verscheen. Het zou een doorbraak betekenen als dit op grote schaal mogelijk werd, en met name compliance processen en contractenchecks een stuk eenvoudiger maken.
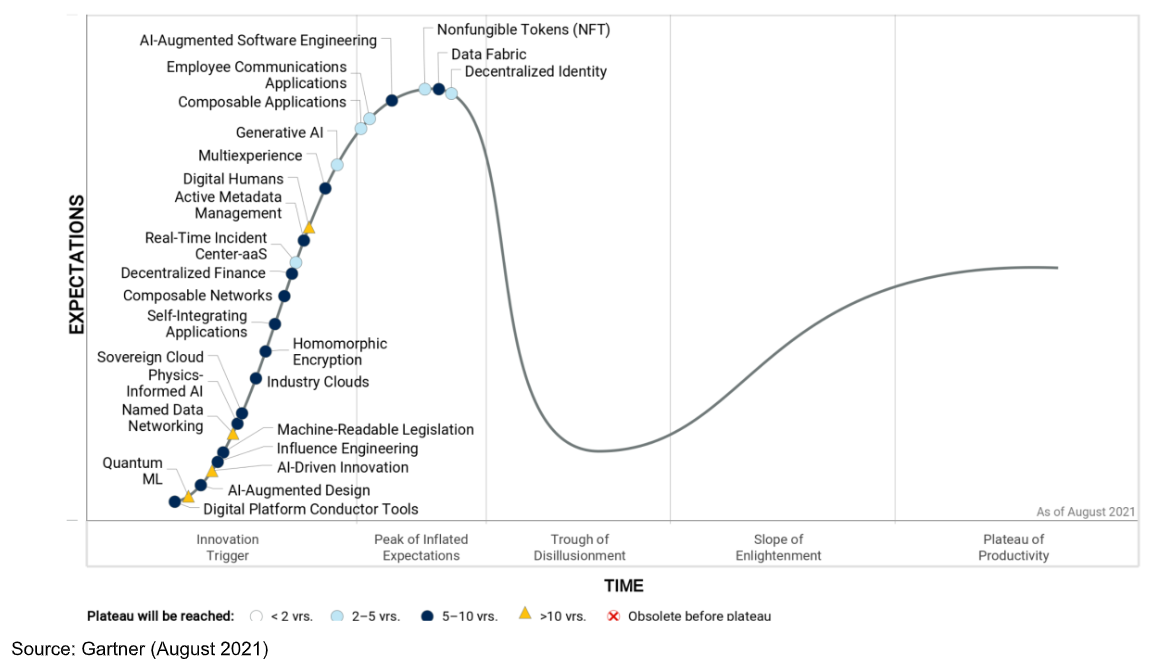
De Gartner Hype Cycle is een handige manier om inzicht te krijgen in opkomende technologieën en trends. Elk jaar publiceert het onderzoeksbureau de ontwikkelingen: van nieuw op de markt naar (te) hoge verwachtingen naar desillusie, inzicht en uiteindelijk productiviteit. Zo zijn de non-fungible tokens (NFT) nu bovenin de hype van te hoge verwachtingen, en is quantum machine learning een net nieuw verschenen technologie. Automatische vertaling van tekst heeft intussen zijn niche gevonden.
Nieuw dit jaar is de “machine-readable legislation”. Traditioneel is gepubliceerde wet- en regelgeving bedoeld voor mensen (met name juristen), en een robot kan daar weinig mee. Steeds vaker proberen wetgevers (en commerciële uitgevers) dergelijke informatie zo aan te bieden dat automatische analyse mogelijk is. Denk aan het toevoegen van metadata waarmee bedragen, datums of afmetingen direct te lezen zijn.
Automatisch herkennen van eisen
Het automatisch kunnen lezen van wettelijke eisen of randvoorwaarden is erg belangrijk voor compliance processen, inclusief het screenen van contracten. Wanneer eisen en voorwaarden immers alleen voor mensen te lezen zijn, blijft controle op naleving puur mensenwerk: interpreteren, toetsen en valideren. Wanneer een computer een eis kan uitlezen en toetsen, wordt deze menselijke factor geautomatiseerd.
Een simpel voorbeeld is een wetswijziging die een bepaalde opzegregeling voor contracten aanpast. Waar voorheen menselijke juristen dan ieder contract moeten doorzoeken op de opzegregeling en deze toetsen aan de nieuwe wet, kan nu een computer dat doen. De enige eis is dat de computer in de contracten kan herkennen welke clausule de opzegregeling bevat, en welke termijnen of andere beperkingen daarbij mogen gelden.
Naar een standaard woordenboek
Het herkennen van clausules en hun varianten gebeurt nu steeds vaker met machine learning, ook wel artificial intelligence (AI) genoemd. Hierbij interpreteert een computer teksten die eigenlijk voor mensen bedoeld zijn. Hoewel hier goede successen mee te behalen zijn, met name bij standaarddocumenten zoals NDA’s of arbeidscontracten, blijft er een risico op foute herkenning. Bij machine-readable legislation is de wet – en het contract – voorzien van metadata, labels die de informatie bevatten op computerleesbare manier. Interpretatie is daardoor niet meer nodig.
De opstap naar het invoeren van deze aanpak is het introduceren van een draaiboek: welke categorieën informatie, welke soorten clausules hebben wij in onze organisatie, en welke varianten staan we daarin toe? Alleen al het hebben van deze informatie maakt nu standaardiseren van juridische processen mogelijk, bijvoorbeeld met contractgeneratie-software. Maar de opstap naar het automatisch controleren van documenten of bedrijfsprocessen wordt dan meteen een stuk simpeler.
De auteur, Arnoud Engelfriet, is partner bij Lynn Legal
